Lab41 Reading Group: Deep Residual Learning for Image Recognition
View as MarkdownThis article originally appeared on Lab41's blog: Gab41. It is reposted here with permission.

Today’s paper offers a new architecture for Convolution Networks. It was written by He, Zhang, Ren, and Sun from Microsoft Research.1 I’ll warn you before we start: this paper is ancient. It was published in the dark ages of deep learning sometime at the end of 2015, which I’m pretty sure means its original format was papyrus; thankfully someone scanned it so that future generations could read it. But it is still worth blowing off the dust and flipping through it because the architecture it proposes has been used time and time again, including in some of the papers we have previously read: Deep Networks with Stochastic Depth
He et al. begin by noting a seemingly paradoxical situation: very deep networks perform more poorly than moderately deep networks, that is, that while adding layers to a network generally improves the performance, after some point the new layers begin to hinder the network. They refer to this effect as network degradation.
If you have been following our previous posts this won’t surprise you; training issues like vanishing gradients become worse as networks get deeper so you would expect more layers to make the network worse after some point. But the authors anticipate this line of reasoning and state that several other deep learning methods, like batch normalization2 (see our post for a summary), essentially have solved these training issues, and yet the networks still perform increasingly poorly as their depth increases. For example, they compare 20- and 56-layer networks and find the 56-layer network performs far worse; see the image below from their paper.
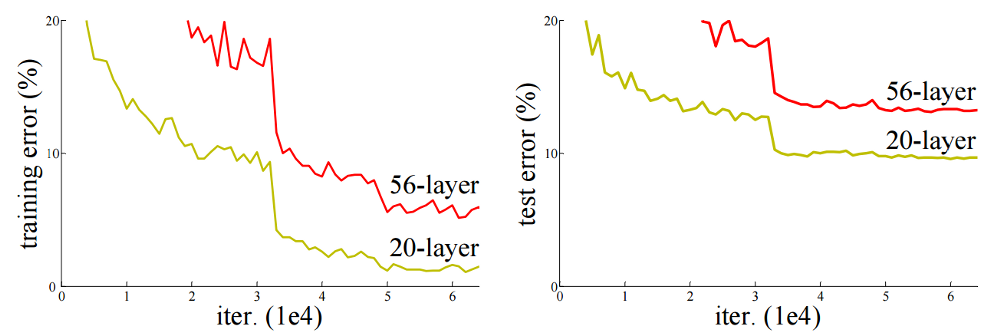
The authors then set up a thought experiment (or gedankenexperiment if you’re a recovering physicist like me) to demonstrate that deeper networks should always perform better. Their argument is as follows:
-
Start with a network that performs well;
-
Add additional layers that are forced to be the identity function, that is, they simply pass along whatever information arrives at them without change;
-
This network is deeper, but must have the same performance as the original network by construction since the new layers do not do anything;
-
Layers in a network can learn the identity function, so they should be able to exactly replicate the performance of this deep network if it is optimal.
This thought experiment leads them to propose their deep residual learning architecture. They construct their network of what they call residual building blocks. The image below shows one such block. These blocks have become known as ResBlocks.

The ResBlock is constructed out of normal network layers connected with rectified linear units (ReLUs) and a pass-through below that feeds through the information from previous layers unchanged. The network part of the ResBlock can consist of an arbitrary number of layers, but the simplest is two.
To get a little into the math behind the ResBlock: let us assume that a set of layers would perform best if they learned a specific function, \(h(x)\). The authors note that the residual, \(f(x) = h(x) − x\), can be learned instead and combined with the original input such that we recover \(h(x)\) as follows: \(h(x) = f(x) + x\). This can be accomplished by adding a \(+x\) component to the network, which, thinking back to our thought experiment, is simply the identity function. The authors hope that adding this “pass-through” to their layers will aid in training. As with most deep learning, there is only this intuition backing up the method and not any deeper understanding. However, as the authors show, it works, and in that end that’s the only thing many of us practitioners care about.
The paper also explores a few modifications to the ResBlock. The first is creating bottleneck blocks with three layers where the middle layer constricts the information flow by using fewer inputs and outputs. The second is testing different types of pass-through connections including learning a full projection matrix. Although the more complicated pass-throughs perform better, they do so only slightly and at the cost of training time.
The rest of the paper tests the performance of the network. The authors find that their networks perform better than identical networks without the pass-through; see the image below for their plot showing this. They also find that they can train far deeper networks and still show improved performance, culminating in training a 152-layer ResNet that outperforms shallower networks. They even train a 1202-layer network to prove that it is feasible, but find that its performance is worse than the other networks examined in the paper.
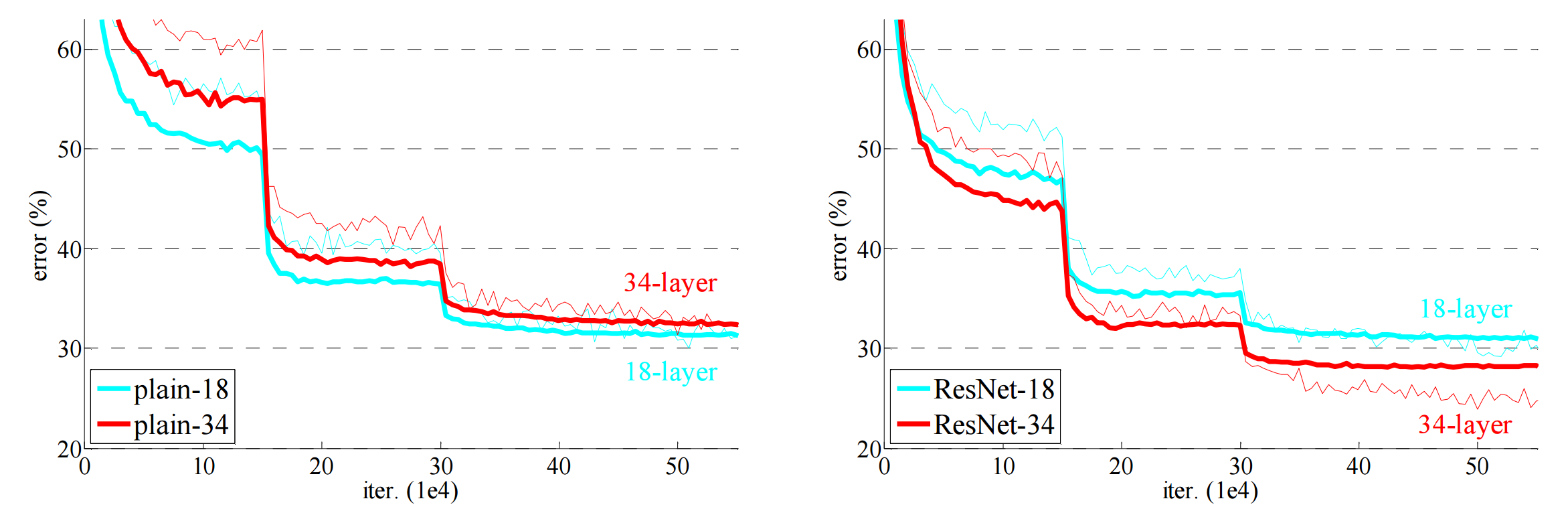
So that’s it! He et al. proposed a new architecture motivated by thought experiments and the hope that it will work better than previous ones. They construct several networks, including a few very deep ones, and find that their new architecture does indeed improve performance of the networks. Although we don’t gain any further understanding of the underlying principles of deep learning, we do get a new method of making our networks work better, and in the end maybe that’s good enough.
-
He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian. “Deep Residual Learning for Image Recognition” 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2016. pp. 770–778. doi: 10.1109/CVPR.2016.90. ↩
-
Ioffe, Sergey and Szegedy, Christian. “Batch normalization: accelerating deep network training by reducing internal covariate shift” Proceedings of the 32nd International Conference on International Conference on Machine Learning - Volume 37. JMLR.org. 2015. pp. 448–456. ↩